IMAT Biomolecules II: Proteins & Nucleic Acids
🧬 1. Proteins: The Molecular Machinery
Proteins are complex, unbranched polymers built entirely from specific sequences of amino acids. They are unequivocally the most versatile macromolecules in biological systems, acting as structural beams, molecular motors, transport vessels, immunological barriers, and chemical catalysts (enzymes). They contain Carbon, Hydrogen, Oxygen, Nitrogen, and frequently Sulfur ($\mathrm{C, H, O, N, S}$).

The Monomers: Amino Acids
There are 20 standard, proteinogenic amino acids encoded by the universal genetic code. Regardless of their variable side chains, every single amino acid shares an identical foundational backbone centered around an alpha carbon ($\mathrm{C_\alpha}$).

The central $\mathrm{C_\alpha}$ is covalently bonded to four distinct substituents:
- Amino Group ($-\mathrm{NH_2}$): A basic functional group that can accept a proton ($\mathrm{H^+}$) to become positively charged ($-\mathrm{NH_3^+}$).
- Carboxyl Group ($-\mathrm{COOH}$): An acidic functional group that can donate a proton ($\mathrm{H^+}$) to become negatively charged ($-\mathrm{COO^-}$).
- Hydrogen Atom ($-\mathrm{H}$).
- Variable R-Group (Side Chain): The defining chemical moiety. It dictates the chemical identity and physical behavior (hydrophobic, hydrophilic, charged, aromatic, or chemically reactive).
Molecular Chirality & Special Amino Acids
Because the central alpha-carbon is bonded to four distinct groups, it represents a Chiral Center (stereocenter). Therefore, amino acids exist as two non-superimposable mirror-image enantiomers: L-isomers and D-isomers. Ribosomal machinery exclusively utilizes L-Amino Acids to synthesize proteins. D-amino acids are not found in proteins, occurring only in bacterial cell walls and specialized non-ribosomal peptides.
Three amino acids possess highly specific structural characteristics critical for the IMAT:
- Glycine ($\mathrm{Gly}$, $\mathrm{G}$): The smallest amino acid. Its R-group is a simple hydrogen atom ($-\mathrm{H}$), making it the only achiral standard amino acid. It possesses high conformational flexibility, allowing it to fit into tight structural spaces like the core of the collagen triple helix.
- Proline ($\mathrm{Pro}$, $\mathrm{P}$): Possesses a cyclic pyrrolidine side chain that covalently binds back to the amino group, forming a rigid secondary amine. This structure severely restricts dihedral angles, introducing rigid "kinks" that disrupt standard $\alpha$-helices and $\beta$-sheets.
- Cysteine ($\mathrm{Cys}$, $\mathrm{C}$): Features a highly reactive thiol group ($-\mathrm{SH}$). Under oxidizing conditions (such as the extracellular space), two adjacent cysteine residues can undergo oxidation to form a covalent disulfide bridge ($\mathrm{-S-S-}$), which strongly stabilizes tertiary and quaternary protein folds.
Because amino acids contain both basic and acidic groups, they are amphoteric substances (ampholytes). At physiological pH ($\approx 7.4$), they undergo an internal neutralization transfer of a proton from the carboxyl group to the amine group.
- The Carboxyl group exists as a carboxylate anion: $-\mathrm{COOH} \rightarrow -\mathrm{COO^-}$
- The Amino group exists as an ammonium cation: $-\mathrm{NH_2} \rightarrow -\mathrm{NH_3^+}$
This dipolar state is called a Zwitterion. The molecule has positive and negative charges, yet is net neutral.
The pI is the precise pH at which the net charge of an amino acid population is exactly zero. It can be mathematically calculated as the average of the $\mathrm{p}K_a$ values of the groups involved in the transition: $$\mathrm{pI} = \frac{\mathrm{p}K_{a1} + \mathrm{p}K_{a2}}{2}$$ If an amino acid is placed in an environment where $\mathrm{pH < pI}$, the high proton concentration forces protonation, giving the molecule a net positive charge. Conversely, if $\mathrm{pH > pI}$, deprotonation occurs, resulting in a net negative charge.
🔗 1.2 Polymerization: The Peptide Bond
Amino acids are linked during translation via condensation reactions. The nucleophilic nitrogen of the amino group of one amino acid attacks the electrophilic carbonyl carbon of another, releasing a water molecule ($\mathrm{H_2O}$) and establishing a covalent peptide bond (amide linkage).


Peptide Bond Resonance & The Ramachandran Plot
The lone pair of electrons on the amide nitrogen is delocalized into the carbonyl $\pi$-system. This resonance creates a partial double bond between the carbon and nitrogen. Consequently, the $\mathrm{C-N}$ peptide bond is rigid, planar, and restricted from rotation, almost always favoring the more stable trans conformation to minimize steric clash between R-groups.
Rotation is only permitted around the single bonds connecting the $\mathrm{C_\alpha}$ to the amide nitrogen (the phi $\phi$ angle) and the carbonyl carbon (the psi $\psi$ angle). The allowed combinations of these angles are plotted on a Ramachandran Plot, which maps out the sterically favorable conformations corresponding to $\alpha$-helices and $\beta$-sheets.
🏢 2. The Hierarchy of Protein Folding
To function, linear polypeptide chains must fold into precise three-dimensional shapes. Folding occurs across four hierarchical levels, stabilized by specific chemical interactions.
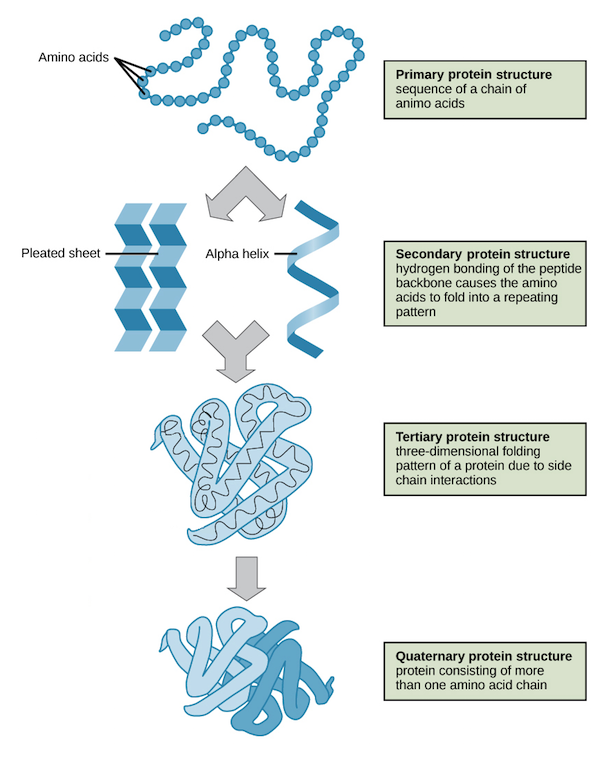

| Level | Structural Details | Stabilizing Forces |
|---|---|---|
| Primary ($1^\circ$) | The linear sequence of amino acids in a polypeptide chain. This sequence is determined by genomic DNA and dictates how higher levels fold. | Covalent Peptide Bonds. |
| Secondary ($2^\circ$) | Local conformations of the polypeptide backbone. Most commonly forms the right-handed $\alpha$-Helix or the folded $\beta$-Pleated Sheet. | Hydrogen Bonds between the carbonyl oxygen ($i$) and the amide hydrogen ($i+4$) of the backbone. R-groups are not involved in these bonds. |
| Tertiary ($3^\circ$) | The overall three-dimensional fold of a single polypeptide chain, bringing distant amino acids into close proximity. | Side chain (R-group) interactions: Hydrophobic collapse, hydrogen bonding, electrostatic salt bridges, and covalent disulfide bridges. |
| Quaternary ($4^\circ$) | The spatial arrangement and functional interaction of multiple polypeptide chains (subunits). E.g., Hemoglobin. | The same non-covalent and covalent interactions as Tertiary structures, but occurring between different polypeptide chains. |

The Hydrophobic Effect & Protein Splicing
Thermodynamically, folding decreases the conformational entropy of the polypeptide chain ($\Delta S_{protein} < 0$). However, folding is driven by the Hydrophobic Effect, which is entropic in nature. When a protein is unfolded, water molecules are forced to form highly ordered "cages" (clathrates) around non-polar side chains. When these hydrophobic side chains collapse into the protein core, the water molecules are released, increasing the entropy of the solvent ($\Delta S_{water} > 0$). This increase in solvent entropy makes the overall folding process thermodynamically favorable ($\Delta G < 0$).
Protein Misfolding & Epigenetics
A single nucleotide substitution in the $\beta$-globin gene (gag $\rightarrow$ gtg) results in a missense mutation where a hydrophilic Glutamic Acid residue is replaced by a hydrophobic Valine residue at position 6 (Glu6Val).
Under deoxygenated conditions, this exposed hydrophobic patch on the protein's surface interacts with hydrophobic regions on adjacent hemoglobin tetramers. This causes the proteins to polymerize into long, rigid fibers that deform the red blood cells into a sickle shape, leading to microvascular occlusion and hemolytic anemia.
When folding fails, proteins can aggregate into insoluble $\beta$-sheet-rich structures called amyloids.
- Alzheimer's Disease: Characterized by extracellular plaques composed of Amyloid-$\beta$ peptides and intracellular neurofibrillary tangles composed of hyperphosphorylated Tau proteins.
- Prion Diseases: Caused by the infectious misfolding of the normal prion protein ($\mathrm{PrP^C}$, predominantly $\alpha$-helical) into the pathological form ($\mathrm{PrP^{Sc}}$, rich in $\beta$-sheets). $\mathrm{PrP^{Sc}}$ acts as a template, forcing healthy proteins to misfold and aggregate, causing transmissible spongiform encephalopathies like Creutzfeldt-Jakob disease.
🧱 3. Fibrous vs. Globular Proteins
Proteins are classified into two broad structural families based on their overall shape and physical properties, which reflect their evolutionary roles.
Characterized by elongated, repeating structures. They are highly insoluble in water because their hydrophobic residues are exposed on the surface, and they play structural roles in tissues.
- Collagen: Composed of a Gly-X-Y repeating tripeptide sequence (where X is typically proline and Y is hydroxyproline). Three left-handed helices wind together to form a tight, right-handed triple helix. This structure provides high tensile strength in bones, skin, and tendons.
- Keratin: An $\alpha$-helical protein rich in cysteine residues, which form disulfide bridges that provide rigidity to hair, nails, and the outer layers of skin.
Folded into spherical, compact shapes. They are highly soluble in water because hydrophobic residues are sequestered in the interior, leaving hydrophilic residues on the exterior. They perform dynamic, regulatory, and metabolic functions.
- Hemoglobin: A tetrameric protein that coordinates oxygen transport through cooperative binding, transitioning between a low-affinity T-state and a high-affinity R-state.
- Myoglobin: A monomeric oxygen-storage protein in muscle tissues that exhibits hyperbolic oxygen-binding kinetics.
- Enzymes: Globular catalysts that utilize specific active-site geometries to accelerate chemical reactions.
⚙️ 4. Enzymes: Reaction Mechanisms & Michaelis-Menten Kinetics
Enzymes are specialized globular protein catalysts. They increase chemical reaction rates by lowering the activation energy barrier ($E_a$), allowing reactions to proceed rapidly under physiological conditions without altering the net free energy change ($\Delta G$) or equilibrium constant ($K_{eq}$).

The rate of an single-substrate enzyme-catalyzed reaction is mathematically modeled by the Michaelis-Menten Equation:
Where:
• $v$ is the initial reaction velocity.
• $V_{max}$ is the maximum velocity when the enzyme is fully saturated with substrate.
• $[S]$ is the substrate concentration.
• $K_m$ is the Michaelis Constant (the substrate concentration at which the velocity is exactly half of $V_{max}$). $K_m$ is inversely proportional to enzyme-substrate affinity; a low $K_m$ indicates high affinity, whereas a high $K_m$ indicates weak binding.

Enzyme Inhibition
| Inhibition Type | Mechanism | Kinetic Effects |
|---|---|---|
| Competitive | The inhibitor structurally resembles the substrate and competes for binding at the Active Site. This effect can be overcome at high substrate concentrations. | $V_{max}$: Unchanged $K_m$: Increases |
| Non-Competitive | The inhibitor binds to an Allosteric Site, changing the enzyme's conformation and reducing catalysis without preventing substrate binding. | $V_{max}$: Decreases $K_m$: Unchanged |
| Uncompetitive | The inhibitor binds exclusively to the Enzyme-Substrate (ES) complex, locking the substrate in the active site and preventing catalytic turnover. | $V_{max}$: Decreases $K_m$: Decreases |
🧪 5. Lab Assay: The Biuret Test
The Biuret test is a qualitative chemical assay used to detect the presence of peptide bonds in a sample.
Reaction Chemistry
Mechanism: The Biuret reagent contains an alkaline solution of Copper(II) sulfate ($\mathrm{CuSO_4}$). In basic environments, the divalent copper ions ($\mathrm{Cu^{2+}}$) form a coordination complex with the peptide nitrogens of a polypeptide. This complex shifts the absorption spectrum of the solution, changing its color from light blue to a deep violet/purple.
🧬 6. Nucleic Acids: Structure of Nucleotides
Nucleic acids (DNA and RNA) store, transmit, and express genetic information. They are polymers composed of monomeric units called Nucleotides.
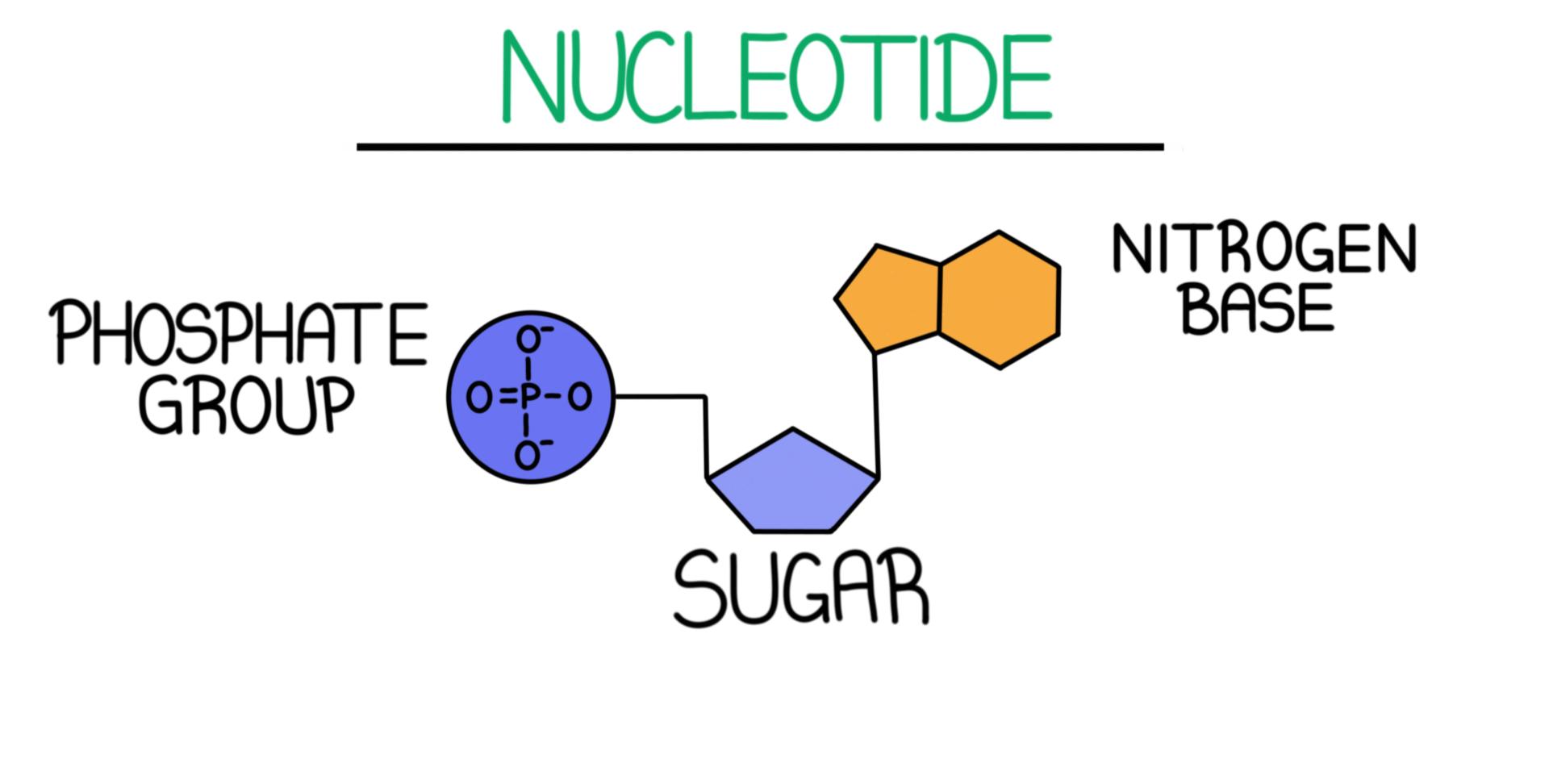


Components of a Nucleotide
Attached to the $5'$ carbon of the pentose sugar. It is highly acidic and negatively charged at physiological pH, giving DNA and RNA their overall negative charge density.
A 5-carbon furanose ring.
• RNA contains Ribose, which features a hydroxyl ($-OH$) group on the $2'$ carbon.
• DNA contains Deoxyribose, which lacks this oxygen atom on the $2'$ carbon ($-\mathrm{H}$ instead of $-\mathrm{OH}$). This absence makes DNA less susceptible to hydrolysis and significantly more chemically stable than RNA.
Attached to the $1'$ carbon of the sugar ring via an N-glycosidic bond. These nitrogen-rich aromatic rings are classified into two groups:
Double-ring structures consisting of Adenine ($\mathrm{A}$) and Guanine ($\mathrm{G}$). Mnemonic: "Pure As Gold"
Single-ring structures consisting of Cytosine ($\mathrm{C}$), Thymine ($\mathrm{T}$, DNA only), and Uracil ($\mathrm{U}$, RNA only). Mnemonic: "Cut The Py"
Phosphodiester Bonds & Backbone Directionality
Nucleotides polymerize via covalent Phosphodiester Bonds. During synthesis, DNA/RNA polymerase joins the $5'$ phosphate group of an incoming nucleoside triphosphate to the exposed $3'$ hydroxyl group of the existing chain, releasing pyrophosphate ($\mathrm{PP_i}$). This reaction establishes a repeating Sugar-Phosphate Backbone with base pairs oriented internally. Consequently, all nucleic acid strands possess directionality, defined by a free $5'$ phosphate end and a free $3'$ hydroxyl end. Synthesis always proceeds in the $5' \rightarrow 3'$ direction.
🧬 7. DNA Architecture & Epigenetics



Structural Rules of the Double Helix
The double-stranded helix of DNA (specifically B-DNA) is characterized by several physical and chemical properties:
- Antiparallel Orientation: The two backbones run in opposite directions ($5' \rightarrow 3'$ opposite $3' \rightarrow 5'$). This arrangement is required for nitrogenous bases to project inward and form hydrogen bonds.
- Complementary Base Pairing: To maintain a constant helical diameter of 2.0 nm, a double-ring purine must always pair with a single-ring pyrimidine:
- Adenine pairs with Thymine ($\mathrm{A=T}$) via two hydrogen bonds.
- Guanine pairs with Cytosine ($\mathrm{G \equiv C}$) via three hydrogen bonds.
Thermodynamic Stability: Due to the extra hydrogen bond, $\mathrm{G-C}$ pairs are more stable than $\mathrm{A-T}$ pairs. Consequently, DNA regions rich in $\mathrm{G-C}$ require higher temperatures to denature (melt).
- Chargaff's Rules: In double-stranded DNA, the concentration of purines equals the concentration of pyrimidines ($\mathrm{\%A = \%T}$ and $\mathrm{\%G = \%C}$), meaning $\mathrm{A + G = T + C}$.
- Helical Dimensions & Grooves: B-DNA has a helical pitch of 3.4 nm per turn, containing approximately 10.4 base pairs, resulting in a rise of 0.34 nm per base pair. The twisting of the backbones creates asymmetrical spaces: the Major Groove (broad and deep) and the Minor Groove (narrow). Transcription factors and DNA-binding proteins typically recognize specific sequences by binding to the major groove, where base pairs are more exposed.
DNA Packaging & Chromatin Epigenetics

DNA is packed into chromatin by wrapping around Histones. Histones are small, globular proteins rich in positively charged residues (Lysine and Arginine) that form electrostatic interactions with the negatively charged DNA phosphate backbone.
- The Nucleosome Core: Composed of an octamer of core histones (two copies each of H2A, H2B, H3, and H4). Approximately 146 base pairs of DNA wrap around this octamer core 1.65 times, locked in place by linker histone H1. Under electron microscopy, this forms a "beads-on-a-string" structure.
- Chromatin Remodeling & Epigenetics: The state of DNA compaction regulates gene transcription:
• Histone Acetylation: Histone acetyltransferases (HATs) add acetyl groups to lysine residues on histone tails. This neutralizes their positive charges, weakening their electrostatic interactions with DNA. This relaxes chromatin into Euchromatin, allowing transcription machinery to access DNA.
• Histone Deacetylation: Histone deacetylases (HDACs) remove these acetyl groups, restoring the positive charge on histones. This compacts chromatin into Heterochromatin, silencing gene expression.
📜 8. RNA Diversity, Central Dogma & Bioenergetics
Unlike double-stranded DNA, RNA is typically single-stranded and can fold into complex three-dimensional shapes. RNA contains ribose as its sugar and utilizes Uracil ($\mathrm{U}$) instead of Thymine ($\mathrm{T}$).

| Type | Secondary Structure | Function |
|---|---|---|
| mRNA | Unfolded, linear | Messenger RNA. Transcribes genetic code from DNA in the nucleus and carries it to the ribosomes. Its sequence is read in triplets called Codons. |
| tRNA | Folded, Cloverleaf / L-shape | Transfer RNA. Delivers specific amino acids to the ribosome. It features an Anticodon loop that pairs with the mRNA codon, and a $3'$ CCA terminal acceptor stem where the amino acid is attached. |
| rRNA | Complex folded complexes | Ribosomal RNA. Composes the structural and catalytic core of ribosomes. rRNA acts as a Ribozyme, catalyzing peptide bond formation during translation. |
Splicing & Spliceosomes
Eukaryotic pre-mRNA transcripts contain coding segments called exons and non-coding segments called introns. Before leaving the nucleus, introns must be removed and exons joined together. This process is called Splicing and is catalyzed by a protein-RNA complex called the Spliceosome.
The spliceosome is composed of small nuclear RNAs (snRNAs) complexed with proteins to form snRNPs (small nuclear ribonucleoproteins). Through Alternative Splicing, a single gene can produce multiple distinct protein isoforms by combining different exons, expanding eukaryotic protein diversity.
9. The Central Dogma of Molecular Biology
The flow of sequence-specific genetic information inside living cells follows a defined pathway:
Occurs in the Nucleus. RNA Polymerase reads the DNA template strand in the $3' \rightarrow 5'$ direction to synthesize a complementary mRNA transcript in the $5' \rightarrow 3'$ direction.
Occurs in the Cytoplasm on the ribosome. The ribosome translates mRNA codons into a polypeptide chain using amino-acid-carrying tRNAs.
9.1 Properties of the Genetic Code
The genetic code translates the four-letter nucleotide sequence of mRNA into the twenty-letter amino acid sequence of proteins based on three principles:
⚡ 10. ATP: Bioenergetics
Adenosine Triphosphate (ATP) is an RNA nucleotide derivative consisting of the base Adenine, the sugar Ribose, and three phosphate groups.
The three adjacent phosphate groups in ATP carry negative charges that repel one another. This electrostatic repulsion makes the covalent phosphoanhydride bonds linking the phosphates unstable.
The cleavage of the terminal phosphate bond via hydrolysis is highly exergonic, releasing approximately $30.5\text{ kJ/mol}$ of free energy ($\Delta G = -30.5\text{ kJ/mol}$). Cells couple this exergonic reaction to endergonic cellular processes to drive work.
📝 Mastery Practice: IMAT Biomolecules II Quiz
Test your understanding of protein structure, enzyme kinetics, and nucleic acid biochemistry. These questions are modeled after the integrated reasoning style of the IMAT exam.